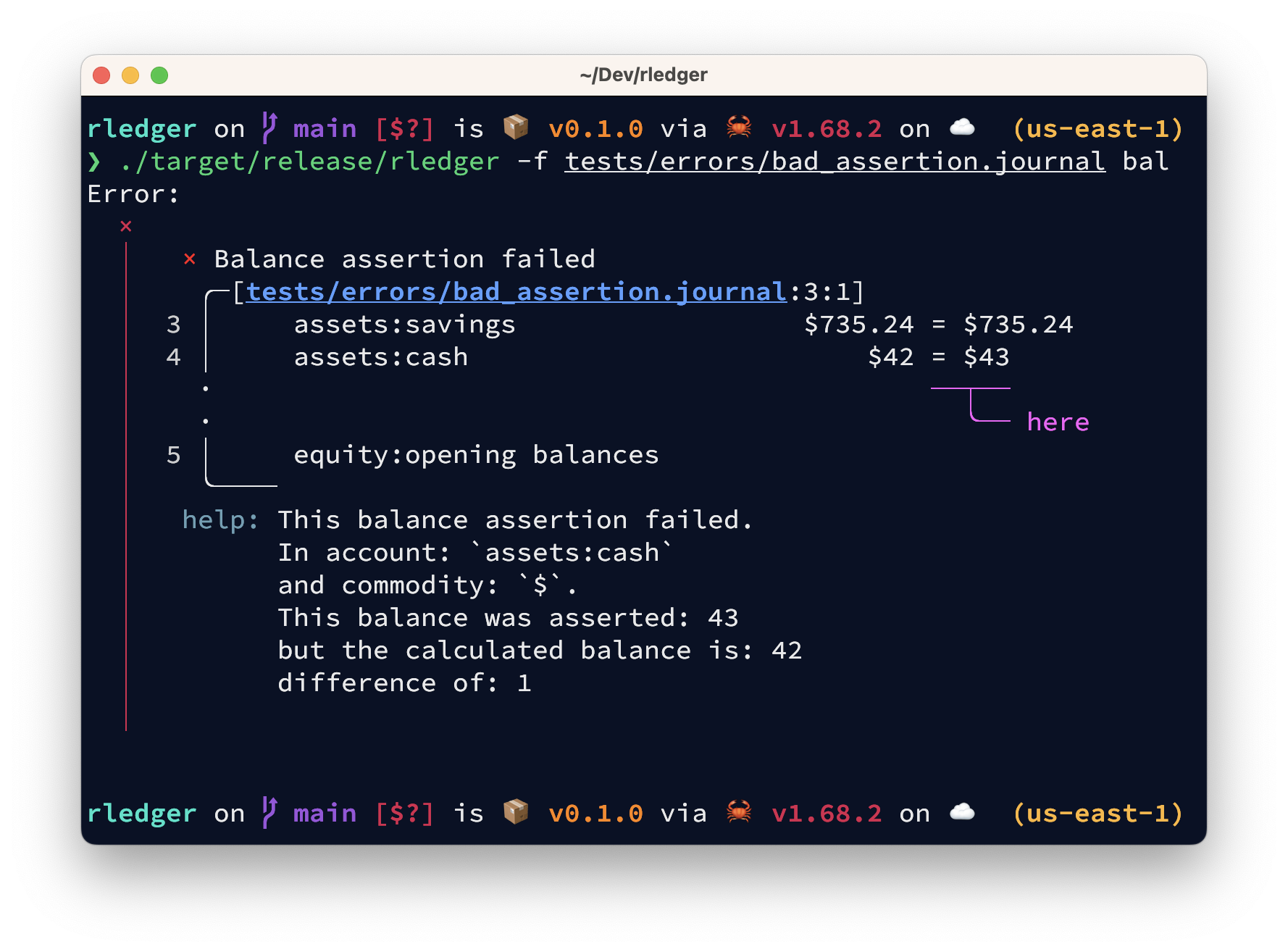
On an AMD Ryzen 9 5950X 16-Core Processor, I am getting 275,549 transactions per second 🚀.
By comparison, hledger is running at 13,982 per second.
rledger is now ~19x faster than hledger 🤯⚡.
Run benchmarks using criterion with cargo bench. This will show how performance has changed between runs.
Ad hoc tests can be taken with hyperfine:
cargo build --release
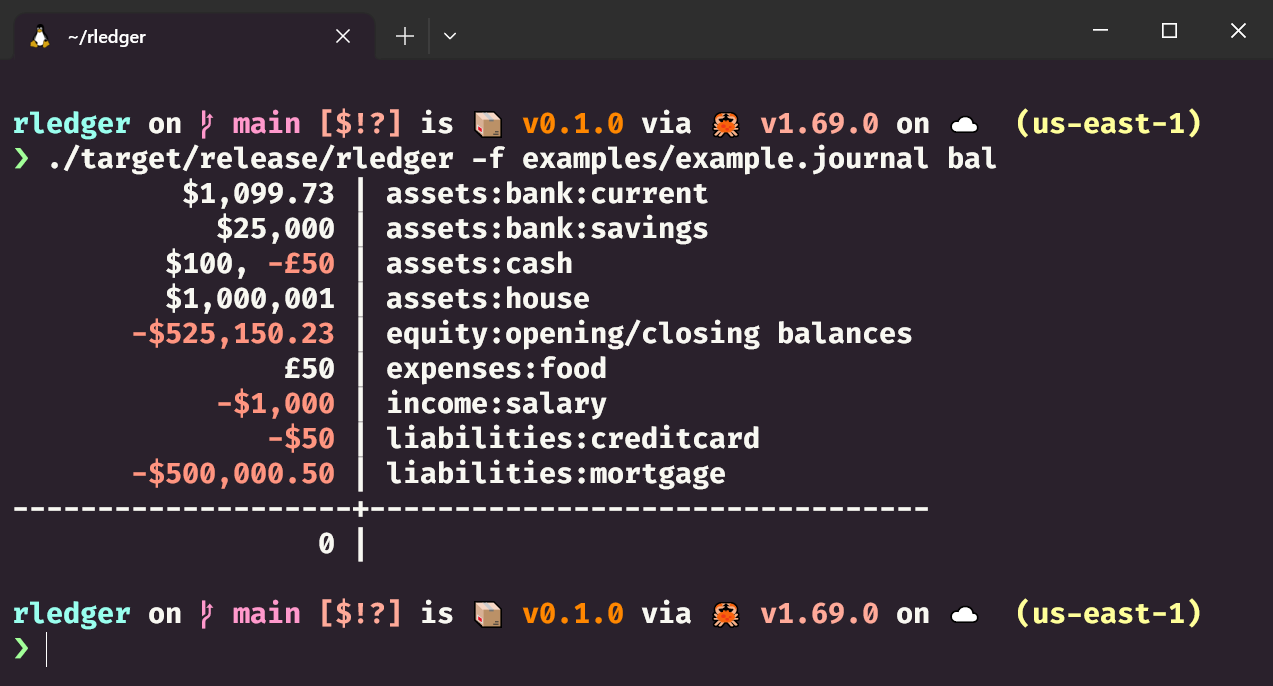
hyperfine './target/release/rledger -f benches/10000x1000x10.journal bs'
This approach is good for comparing performance with hledger (how the results above were found):
hyperfine -w 5 './target/release/rledger -f benches/10000x1000x10.journal bs' 'hledger -f benches/10000x1000x10.journal bs'